
Minimising Recursive Data Types
Following on from my previous post about structural subtyping with recursive types, a related problem is that of minimising recursive types. Consider this (somewhat artificial) example:
define InnerList as null | { int data, OuterList next }
define OuterList as null | { int data, InnerList next }
int sum(OuterList list):
if list ~= null:
return 0
else:
return 1 + sum(list.next)
This defines a simple Linked list data structure using two separate types: OuterList and InnerList. Under structural subtyping, an OuterList is equivalent to an InnerList and both are equivalent to this (more common) definition:
define LinkedList as null | { int data, LinkedList next }
We can draw some nice pictures to help illustrate this issue of equivalence:
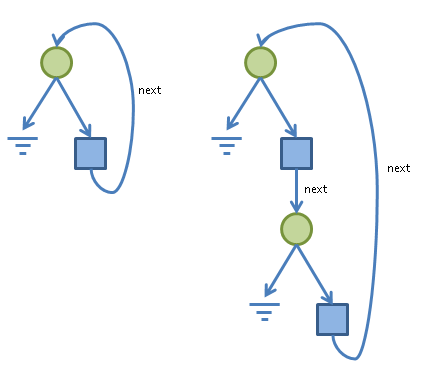
Here, circles represent the union of types (e.g. X | Y), whilst the squares represent the records (e.g. { int data, ... }). The type on the left corresponds with LinkedList, whilst that on the right corresponds with OuterList (note: I’ve left off the data field from the diagrams as it’s not important here).
One way to think about why these types are equivalent is to consider that they “accept” the same concrete list instances. Here are some example lists with one, two and three nodes respectively:
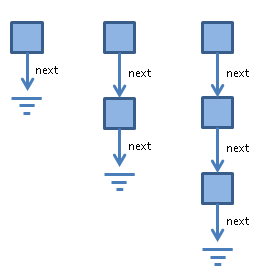
To determine whether one of our types LinkedList or OuterList will accept one of these concrete instances is easy enough:
Set
iandjas the root of the recursive and concrete trees (respectively).If nodes at
iandjare bothnull, then return ACCEPT.If node at
iis a union (i.e. circle), then advanceidown one branch, and repeat from step 2. If this results in NOTACCEPT, backtrack and advanceidown the other branch.If nodes at
iandjare both records (i.e. squares), then check they have same fields. If so, advance bothiandjdown the same labelled branch and check this gives ACCEPT; repeat for all labelled branches and, if all OK, return ACCEPT.Otherwise, return NOTACCEPT
By applying this procedure, we find both LinkedList and OuterList accept all of the concrete instances given above. In fact, they accept exactly the same set of concrete instances and, hence, are equivalent.
Clearly, LinkedList is a more compact representation than OuterList. So, we want to automatically minimise recursive types such that, for example, OuterList reduces to LinkedList for us. Doing this helps, amongst otherthings, simplify the implementation of the subtype operator considerably (see the technical report for more on that). It turns out that we can borrow ideas from automata theory (specifically, DFA minimisation) to help with this minimisation problem (see this and this for introductions).
The basic idea is that we want to identify nodes within our recursive types which are equivalent. What we’ll do is initially assume that all states are equivalent. Then, we’ll cross off those equivalences which are patently untrue (for example, a records are only equivalent to records, etc). We then repeat this process until we reach a fixed point (i.e. no further things to cross off), at which point we have our solution. For example, consider our OuterList type again:
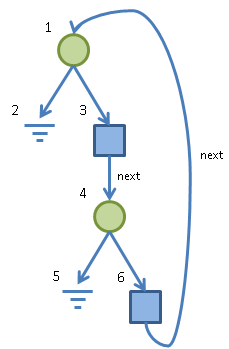
This time I’ve annotated each node with a unique number. Then, we start off with a single equivalent set: {1,2,3,4,5,6}. Immediately, we can split this out into equivalences {2,5}, {1,4} and {3,6} because, for example, node 2 cannot be equivalent to node 3 since they have different type. At this point, we’re actually finished already since the example was quite simple.